Introducing the JetStream 2 Benchmark Suite
Today we are announcing a new version of the JetStream JavaScript benchmark suite, JetStream 2. JetStream 2 combines a variety of JavaScript and WebAssembly benchmarks, covering an array of advanced workloads and programming techniques, and reports a single score that balances them using a geometric mean. JetStream 2 rewards browsers that start up quickly, execute code quickly, and run smoothly. Optimizing the overall performance of our JavaScript engine has always been a high priority for the WebKit team. We use benchmarks to motivate wide-reaching and maintainable optimizations to the WebKit engine, often leading us to make large architectural improvements, such as creating an entirely new optimizing compiler, B3, in 2015. JetStream 2 mixes together workloads we’ve been optimizing for years along with a new set of workloads we’ll be improving for years to come.
When we released JetStream 1 in 2014, it was a cross-cutting benchmark, measuring the performance of the latest features in the JavaScript ecosystem, at that time. One of our primary goals with JetStream 1 was to have a single benchmark we could use to measure overall JavaScript performance. However, since 2014, a lot about the JavaScript ecosystem has changed. Two of the major changes were the release of an extensive update to the JavaScript language in ES6, and the introduction of an entirely new language in WebAssembly. Even though we created JetStream 1 as a benchmark to track overall engine performance, we found ourselves creating and using new benchmarks in the years since its release. We created ARES-6 in 2017 to measure our performance on ES6 workloads. For the last two years, we’ve also tracked two WebAssembly benchmarks internal to the WebKit team. In late 2017, the V8 team released Web Tooling Benchmark, a benchmark we’ve used to improve regular expression performance in JavaScriptCore. Even though JetStream 1 was released after Kraken, we found ourselves continuing to track Kraken after its release because we liked certain subtests in it. In total, prior to creating JetStream 2, the WebKit team was tracking its performance across six different JavaScript and WebAssembly benchmarks.
Gating JavaScriptCore’s performance work on a relative ordering of six different benchmark suites is impractical. It proved non-obvious how to evaluate the value of a change based on the collective results of six different benchmark suites. With JetStream 2, we are moving back to having a single benchmark — which balances the scores of its subtests to produce a single overall score — to measure overall engine performance. JetStream 2 takes the best parts of these previous six benchmarks, adds a group of new benchmarks, and combines them into a single new benchmark suite. JetStream 2 is composed of:
- Almost all JetStream 1 benchmarks.
- New benchmarks inspired by subtests of Kraken.
- All of ARES-6.
- About half of the Web Tooling Benchmark.
- New WebAssembly tests derived from the asm.js benchmarks of JetStream 1.
- New benchmarks covering areas not tested by the other six benchmark suites.
New Benchmarks
JetStream 2 adds new benchmarks measuring areas not covered by these previous benchmark suites. An essential component of JetStream 1 was the asm.js subset of benchmarks. With the release of WebAssembly, the importance of asm.js has lessened since many users of asm.js are now using WebAssembly. We converted many of the asm.js benchmarks from JetStream 1 into WebAssembly in JetStream 2. We also created a few new WebAssembly benchmarks. One such new test is richards-wasm, which models a hybrid JS and WebAssembly application. Richards-wasm is an implementation of Martin Richard’s system language benchmark that is implemented partially in WebAssembly and partially in JavaScript. The benchmark models a JavaScript application that frequently calls into helper methods defined in WebAssembly.
JetStream 2 adds two new Web Worker tests. It’s essential for JetStream 2 to measure Web Worker performance given how popular they are across the web. The first worker benchmark we created is bomb-workers. Bomb-workers runs all of SunSpider in parallel — so it stresses how well the browser handles running a lot of JavaScript in parallel. The second benchmark we created is segmentation. Segmentation runs four Web Workers in parallel to compute the time series segmentation over a sample data set. This benchmark is derived from the same algorithm used in WebKit’s performance dashboard.
JetStream 2 adds three new benchmarks emphasizing regular expression performance: OfflineAssembler, UniPoker, and FlightPlanner. UniPoker and FlightPlanner stress the performance of Unicode regular expressions — a feature that was new in ES6. OfflineAssembler is the JavaScriptCore offline assembler parser and AST generator translated from Ruby into JavaScript. UniPoker is a 5 card stud poker simulation using the Unicode code points for playing cards to represent card values. FlightPlanner parses aircraft flight plans that consist of named segments, e.g. takeoff, climb, cruise, etc, that include waypoints, airways, or directions and times, and then processes those segments with an aircraft profile to compute course, distance and forecast times for each resulting leg in the flight plan, as well as the total flight plan. It exercises Unicode regular expression code paths because the segment names are in Russian.
JetStream 2 also adds two new general purpose JavaScript benchmarks: async-fs and WSL. Async-fs models performing various file system operations, such as adding and removing files, and swapping the byte-order of existing files. Async-fs stresses the performance of DataView, Promise, and async-iteration. WSL is an implementation of an early version of WHLSL — a new shading language proposal for the web. WSL measures overall engine performance, especially stressing various ES6 constructs and throw.
You can read about each benchmark in JetStream 2 in the summary page.
Benchmarking Methodology
Each benchmark in JetStream 2 measures a distinct workload, and no single optimization technique is sufficient to speed up all benchmarks. Some benchmarks demonstrate tradeoffs, and aggressive or specialized optimizations for one benchmark might make another benchmark slower. Each benchmark in JetStream 2 computes an individual score. JetStream 2 weighs each benchmark equally.
When measuring JavaScript performance on the web, it’s not enough to just consider the total running time of a workload. Browsers may perform differently for the same JavaScript workload depending on how many times it has run. For example, garbage collection runs periodically, making some iterations take longer than others. Code that runs repeatedly gets optimized by the browser, so the first iteration of any workload is usually more expensive than the rest.
For this reason, JetStream 1 categorized each benchmark into one of two buckets: latency or throughput. Latency tests either measured startup performance or worst case performance. Throughput tests measured sustained peak performance. Like JetStream 1, JetStream 2 measures startup, worst case, and peak performance. However, unlike JetStream 1, JetStream 2 measures these metrics for every benchmark.
JetStream 2 scores JavaScript and WebAssembly differently. For all but one of the JavaScript benchmarks in JetStream 2, individual benchmark scores equally weigh startup performance, worst case performance, and average case performance. These three metrics are crucial to running performant JavaScript in the browser. Fast startup times lead browsers to loading pages more quickly and allow users to interact with the page sooner. Good worst case performance ensures web applications run without hiccups or visual jank. Fast average case performance makes it so that the most advanced web applications can run at all. To measure these three metrics, each of these benchmarks run for N iterations, where N is usually 120, but may vary based on the total running time of each iteration. JetStream 2 reports the startup score as the time it takes to run the first iteration. The worst case score is the average of the worst M iterations, excluding the first iteration. M is always less than N, and is usually 4. For some benchmarks, M can be less than 4 when N is smaller than 120. The average case score is the average of all but the first of the N iterations. These three metrics are weighed equally using the geometric mean.
WSL is JetStream 2’s one JavaScript benchmark that is an exception to the above scoring technique. WSL uses a different scoring mechanism because it takes orders of magnitude longer than the other benchmarks to run through a single iteration. It instead computes its score as the geometric mean over two metrics: the time it takes to compile the WSL standard library, and the time it takes to run through the WSL specification test suite.
JetStream 2’s WebAssembly benchmarks are scored in two parts that equally weigh startup time and total execution time. The first part is the startup time, which is the time it takes until the WebAssembly module is instantiated. This is the time it takes the browser to put the WebAssembly code in a runnable state. The second part is the execution time. This is the time it takes to run the benchmark’s workload after it is instantiated. Both metrics are crucial for JetStream 2 to measure. Good startup performance makes it so that WebAssembly applications load quickly. Good execution time makes it so WebAssembly benchmarks run quickly and smoothly.
In total, JetStream 2 includes 64 benchmarks. Each benchmark’s score is computed as outlined above, and the final score is computed as the geometric mean of those 64 scores.
Optimizing Regular Expressions
The Web Tooling Benchmark made us aware of some performance deficiencies in JavaScriptCore’s Regular Expression processing and provided a great way to measure any performance improvements for changes we made. For some background, the JavaScriptCore Regular Expression engine, also know as YARR, has both a JIT and interpreter matching engine. There were several types of patterns that were commonly used in the WebTooling Benchmark tests that JavaScriptCore didn’t have support for in the YARR JIT. This included back references, and nested greedy and non-greedy groups.
A back reference takes the form of /^(x*) 123 \1$/, where we match what is in the parenthesized group and then match the same thing again later in the string when a prior group is referenced. For the example given here, the string "x 123 x" would match as well as the string “xxxxx 123 xxxxx”. It matches any line that begins with 0 or more 'x', has " 123 " in the middle, and then ends with the same number of 'x' characters as the string started with. JIT support for back references was added for both Unicode and non-Unicode patterns. We also added JIT support for patterns with the ignore case flag that process ASCII and Latin1 strings. Back reference matching of Unicode ignore case patterns is more problematic due to the large amount of case folding data required. So, we revert to the YARR interpreter for Unicode regular expressions that contain back references that also ignore character case.
Before discussing the next improvement we made to the regular expression engine, some background is in order. The YARR Regular Expression engine uses a backtracking algorithm. When we want to match a pattern like /a[bc]*c/, we process forward in the pattern and when we fail to match a term, we backtrack to the prior term to see if we can try the match a little differently. The [bc]* term will match as many b’s and/or c’s in a row as possible. The string “abc” matches the pattern, but it needs to backtrack when matching the 'c' the first time. This happens because the middle [bc]* term will match both the 'b' and the 'c', and when we try to match the final 'c' term in the pattern, the string has been exhausted. We backtrack to the [bc]* term and reduce the length of that term’s match from “bc” to just “b” and then match the final 'c' term. This algorithm requires state information to be saved for various term types so that we can backtrack. Before we started this work, backtracking state consisted of counts and pointers into the term’s progress in a subject string.
We had to extend how backtracking state was saved in order to add support for counted captured parenthesized groups that are nested within longer patterns. Consider a pattern like /a(b|c)*bc/. In addition to the backtracking information for the contents of the captured parenthesized group, we also need to save that group’s match count, and start and end locations as part of the captured group’s backtracking state. This state is saved in nodes on a singly linked list stack structure. The size of these parenthesized group backtracking nodes is variable, depending on the amount of state needed for all nested terms including the nested capture group’s extents. Whenever we begin matching a parenthesized group, either for the first or a subsequent time, we save the state for all the terms nested within that group as a new node on this stack. When we backtrack to the beginning of a parenthesized group, to try a shorter match or to backtrack to the prior terms, we pop the captured group’s backtracking node and restore the saved state.
We also made two other performance improvements that helped our JetStream 2 performance. One is matching longer constant strings at once and the other is canonicalizing constructed character classes. We have had the optimization to match multiple adjacent fixed characters in a pattern as a group for some time, where we could match up to 32bits of character data at once, e.g four 8 bit characters. Consider the expression /starting/, which simply looks for the string “starting”. These optimizations allowed us to match “star” with one 32 bit load-compare-branch sequence and then the trailing “ting” with a second 32 bit load-compare-branch sequence. The recent change was made for 64 bit platforms and allows us to match eight 8 bit characters at a time. With this change, this regular expression is now matched with a single 64 bit load-compare-branch sequence.
The latest Regular Expression performance improvement we did that provided some benefit to JetStream 2 was to coalesce character classes. For background, character classes can be constructed from individual characters, ranges of characters, built in escape characters, or built in character classes. Prior to this change, the character class [\dABCDEFabcdef], which matches any hex digit, would check for digit characters by comparing a character value against ‘0’ and ‘9’, and then individually compare it against each of the alphabetic characters, 'A', 'B', etc. Although this character class could have been written as [\dA-Fa-f], it makes sense for YARR to do this type of optimization for the JavaScript developer. Our change to character class coalescing now does this. We merge individual adjacent characters into ranges, and adjacent ranges into larger ranges. This often reduces the number of compare and branch instructions. Before this optimization, /[\dABCDEFabcdef]/.exec(“X”) would require 14 compares and branches to determine there wasn’t a match. Now it takes just 4 compares and branches.
The performance impact of these optimizations was dramatic for some of the Web Tooling Benchmark tests. Adding the ability to JIT greedy nested parens improved the performance of coffeescript by 6.5x. JIT’ing non-greedy nested parens was a 5.8x improvement to espree and a 3.1x improvement to acorn. JIT’ing back references improved coffeescript by another 5x for a total improvement of 33x on that test. These changes also had smaller, but still measurable improvements on other JetStream 2 tests.
Performance Results
The best way for us to understand the state of performance in JavaScriptCore is both to track our performance over time and to compare our performance to other JavaScript engines. This section compares the performance of the prior released version of Safari, Safari 12.0.3, the newly released Safari 12.1 from macOS 10.14.4, and the latest released versions of Chrome, Chrome 73.0.3683.86, and Firefox, Firefox 66.0.1.
All numbers are gathered on a 2018 MacBook Pro (13-inch, Four Thunderbolt 3 Ports, MacBookPro15,2), with a 2.3GHz Intel Core i5 and 8GB of RAM. The numbers for Safari 12.0.3 were gathered on macOS 10.14.3. The numbers for Safari 12.1, Chrome 73.0.3683.86, and Firefox 66.0.1 were gathered on macOS 10.14.4. The numbers are the average of five runs of the JetStream 2 benchmark in each browser. Each browser was quit and relaunched between each run.
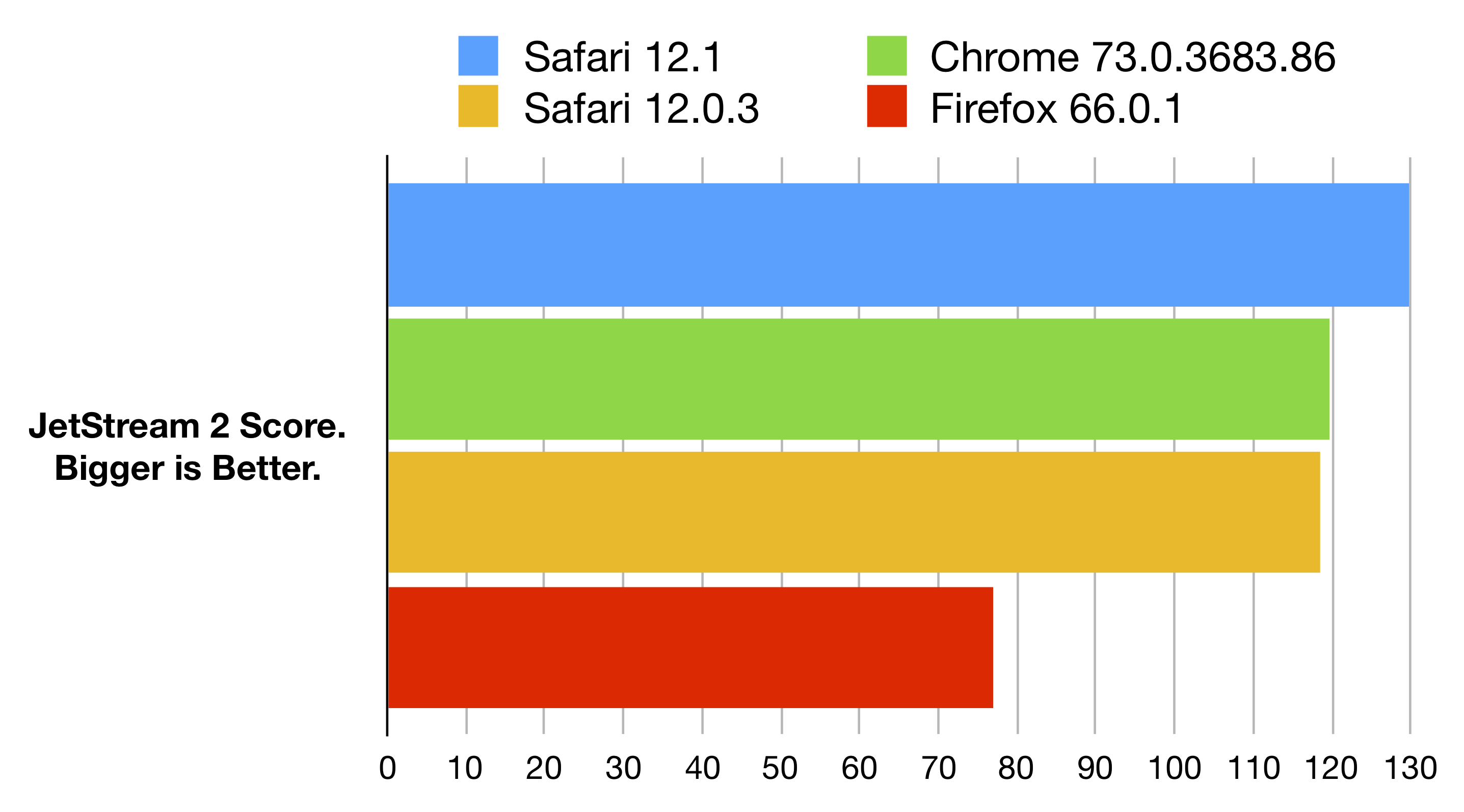
The above figure shows that Safari 12.1 is the fastest browser at running JetStream 2. It is 9% faster than Safari 12.0.3, 8% faster than Chrome 73.0.3683.86, and 68% faster than Firefox 66.0.1.
Conclusion
JetStream 2 is a major update to the JetStream benchmark suite and we’re excited to be sharing it with you today. JetStream 2 includes a diverse set of 64 JavaScript and WebAssembly benchmarks, making it the most extensive and representative JavaScript benchmark we’ve ever released. We believe that engines optimizing for this benchmark will lead to better JavaScript performance on the web. The JavaScriptCore team is focused on improving JetStream 2 and has already made a 9% improvement on it in Safari 12.1.
We’d love to hear any feedback you have on JetStream 2 or the optimizations we’ve made for it. Get in touch with Saam or Michael on Twitter with any feedback you have.